This time we are going to discuss the influence of two basic variables on the quality of SVM classifier. They are called hyperparameters to distinguish them from the parameters optimized in a machine learning procedures. Two previous posts introduced Support Vector Machine itself and data preprocessing for this classifier. As in other Machine Learning techniques there is also a need to properly adjust some system variables to find the best model for our needs. Here, we will focus on description of complexity parameter and gamma parameter from the Gaussian kernel. In the next article we will find an optimum SVM model for the foreground/background estimation problem in Flover project using model validation techniques.
Complexity parameter
Let’s introduce the first hyperparameter of an SVM classifier. It defines its complexity and is also known as regularization or softness parameter indicated by  . This value tells us how many points from the training set are allowed to be on the wrong side of the margin. SVM is always looking for the largest available margin between data groups. The margin is defined as a distance between decision hyperplane and the nearest point from a group, ie. the Support Vector. If all training data points are properly classified, the margin is usually relatively thin so it may be called a hard-margin. But we often deal with a set which is not linearly separable or have some outliers. Then, it’s better to soften the margin and allow for some misclassification in exchange to the grouping generalization. Below is the 2D example of two classes of points which are not linearly separable.
. This value tells us how many points from the training set are allowed to be on the wrong side of the margin. SVM is always looking for the largest available margin between data groups. The margin is defined as a distance between decision hyperplane and the nearest point from a group, ie. the Support Vector. If all training data points are properly classified, the margin is usually relatively thin so it may be called a hard-margin. But we often deal with a set which is not linearly separable or have some outliers. Then, it’s better to soften the margin and allow for some misclassification in exchange to the grouping generalization. Below is the 2D example of two classes of points which are not linearly separable.
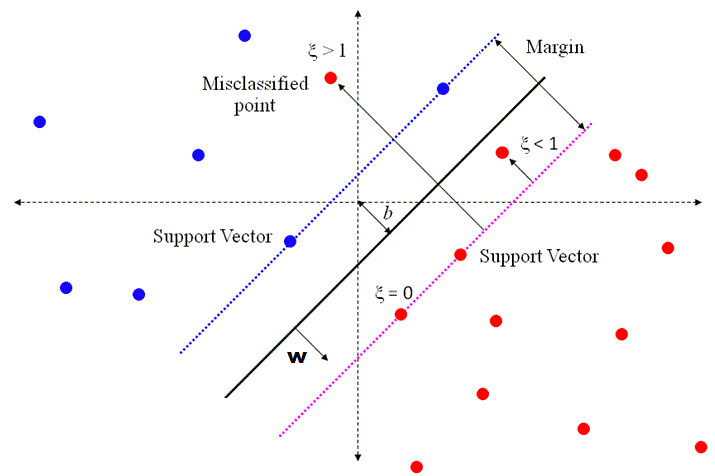
We see two red points which are inside the margin or even wrongly classified. How do we tell a classifier that we accept such soft-margin?
Decision hyperplane is defined by weigth vector  and bias
and bias  . It’s composed from such
. It’s composed from such  points where
points where  . So, it’s simply dividing the plane into two regions. On one side
. So, it’s simply dividing the plane into two regions. On one side  , on another side
, on another side  . Now, to find the widest possible margin which have direct impact on a decision hyperplane the following cost function has to be minimized. Parameters and are the searched variables but comes in some further constraints which are not discussed here.
. Now, to find the widest possible margin which have direct impact on a decision hyperplane the following cost function has to be minimized. Parameters and are the searched variables but comes in some further constraints which are not discussed here.

The second term is a penalty of violating data. It takes all points which are on the wrong side of the margin and sums slack variables  assigned to them (
assigned to them ( – points located in the margin,
– points located in the margin,  – misclassified points). If the complexity parameter is high, we get a hard margin. Otherwise, if is close to
– misclassified points). If the complexity parameter is high, we get a hard margin. Otherwise, if is close to  , the SVM margin is very soft and almost not caring about proper division of data. Therefore, the decision about the adequate complexity parameter is very important to obtain a good SVM model.
, the SVM margin is very soft and almost not caring about proper division of data. Therefore, the decision about the adequate complexity parameter is very important to obtain a good SVM model.
Gamma parameter
In many real-life cases a linear separation of our dataset is not efficient enough. Like presented in one of previous posts about SVM, one can introduce a kernel functions which transforms the data into higher dimensions. Each of these kernels depend on their own parameters. It may be, for instance, a degree of a polynomial kernel or gamma/sigma variable of one of the most popular kernel – a gaussian function. Let’s recall how the  parameter is influencing the width of a Gaussian.
parameter is influencing the width of a Gaussian.

It’s clear that the larger gamma the thinner gaussian curve is. Gaussian kernel in SVM is described as below

Details of the kernel trick and other foundations of SVM theory are very well described in [7]. In short, gaussian kerneling for a point consists in calculation of a sum of Gaussian “bumps” centered around each point  in a training dataset. When is small a given data point has a non-zero kernel value relative to any point in the set. Therefore, the whole set of support vectors affects the value of the discriminant function at , resulting in a smooth decision boundary. This situation is depicted on top-left panel below. As is increased the locality of the support vector expansion increases, leading to greater curvature of the decision boundary. It can be observed on the last panel in the below example.
in a training dataset. When is small a given data point has a non-zero kernel value relative to any point in the set. Therefore, the whole set of support vectors affects the value of the discriminant function at , resulting in a smooth decision boundary. This situation is depicted on top-left panel below. As is increased the locality of the support vector expansion increases, leading to greater curvature of the decision boundary. It can be observed on the last panel in the below example.
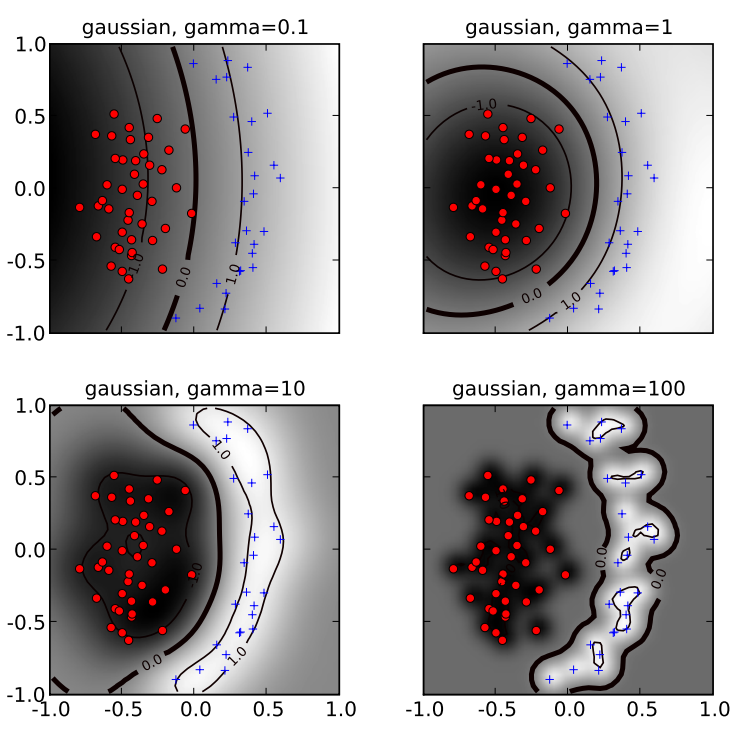
The most dangerous and common effect of increasing is overfitting. It appears when the SVM model is extremely well trained for the training data. But it doesn’t generalize well, i.e. it’s not prepared to respond well for the new, unknown set of data.
Summary
Two hyperparameters which decide about SVM model were presented. Complexity controls the softness of the decision margin. Gaussian kernel bandwidth controls the curvature of a hyperplane. In the next post I will describe how to find them based on a specific SVM case.
I strongly encourage you to play with these parameters here. You can place some points in 2D space and group them using an SVM model with different parameters (-c for complexity and -g for gamma).
Sources:
1. Presentation “Practical guide to SVM” by Tingfan Wu.
2. SVM toy based on libsvm library for Python.
3. SVM tutorial by Jason Weston.
4. Documentation of Shark Machine Learning library for C++.
5. Documentation of scikit-learn library for Python.
6. Topic about SVM variables on StackExchange.
7. Ben-Hur, Weston – “A User’s Guide to Support Vector Machines“.